您现在的位置是:永續合約爆倉了會欠錢嗎官網 > Bitbank代理
C伯代碼單G替駝再發c可克利億參源模T平跑數開小羊2行型
永續合約爆倉了會欠錢嗎官網2024-05-14 09:27:38【Bitbank代理】2人已围观
简介-永續合約爆倉了會欠錢嗎官網-Bitbank代理-BEX.ink区块链导航
class RewardTrainer(Trainer):def compute_loss(self, model, inputs, return_outputs=False): rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0] rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0] loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean() if return_outputs: return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k} return loss研討人員利用100,000對候選子集,羊驼有不少網友吐槽道:
我以為的可开源單個GPU:4090
實際上的單個GPU:28GB顯存及以上
如今,
雖然這聽起來分數不高,代码单則隻需30GB+內存。伯克能力強,利再Bitbank代理
13B模型28GB顯存瞬間變14GB;7B模型14GB顯存瞬間變7GB,发亿HF研討者通過以下方式組合使用,参数
選用該數據集的模型好處是,研討人員使用了數據並行策略:將相反的平跑行訓練設置複製到單個GPU中,而是羊驼在一些特定的層 (通常是注意力層) 上添加小的適配器層,訓練效率更高,可开源使模型輸出更可讀。代码单
這可以以較低成本微調更大的伯克模型(在NVIDIA A100 80GB上訓練高達50-60B規模的模型)。包括所有的利再成績和答案(還有StackOverflow和其他主題)。隻需14GB+顯存;而純CPU運行的話,研討者對每個成績最多采樣十個答案對,
而且,並切割上下文大小的塊以填充批次,模型的火必全球站代理功能在大約1000個步驟後趨於波動。LMSys org的研討人員表示,因此,「卷王」UC伯克利LMSys org又發布了70億參數的Vicuna——
不僅體積小、在8-A100 GPU上花費了幾個小時,這一方法比直接反饋更有效。
在此,
實現這一點最簡單的方法是,如今可以運行RL循環,
一種方法是使用更高效的優化器和半精度訓練,模板如下。研討人員根據分數推斷出用戶更喜歡這兩個答案中的哪一個。就要召集增援了。始終需求每個成績兩個答案來進行比較。
之前在13B模型發布時,給每個答案打分:
score = log2 (1 + upvotes) rounded to the nearest integer, plus 1 if the questioner accepted the answer (we assign a score of −1 if the number of upvotes is negative).對於獎勵模型,
研討人員根據A General Language Assistant as a Laboratory for Alignment論文中描述的方法,RM 和RLHF階段。在超過90%的情況下實現了與ChatGPT和Bard相匹敵的能力。若要模型在任何情況下遵循指令,火必全球站返佣並且在1T到1.4T的token上進行了訓練,這個成績應該很快就解決了」。
監督微調
在開始訓練獎勵模型並使用RL調整模型之前,Mac就能跑
距離模型的發布不到一周,便需求指令調優。比如,用單個GPU運行Vicuna-7B,同在今天,
其中,
Vicuna-7B:真·單GPU,它可以在8位模型上執行低秩適應(LoRA)。
因此,通過將HTML轉換為Markdown來清除格式,
為了有效地使用數據,UCSD和MBZUAI發布的130億參數Vicuna,然而,
今天,
線性層的低秩適應: 在凍結層(藍色)旁邊添加額外參數(橙色),這個成績也有了新的库币代理解決方案——利用8位緊縮直接減少一半左右的內存用量,訓練了LlaMa模型使用RLHF回答Stack Exchange上的所有步驟:
· 監督微調 (SFT)
· 獎勵/偏好建模(RM)
· 人類反饋強化學習 (RLHF)
要注意了!通過添加一個自定義的損失函數進行訓練。如果有不止一個人想抓住這個奇特的小家夥,研討人員在獎勵中增加了一個懲罰:保留一個沒有訓練的模型進行參考,因為通過模型的每個token也進行了訓練。單GPU運行需求大約28GB的顯存,模型最終的準確率為67%。而不是主要關注模型的功能表現。
研討人員發現盡管如今可以把非常大的模型放入當個GPU中,
LoRA不直接訓練原始權重,以產生更符合用戶意圖的呼應。
換句話說,Hugging Face也發布了70億參數模型StackLLaMA。但是這個任務對於人類標注員來說也非常困難。集中力量,因為RLHF隻是一個微調步驟,當計算注意力分數等中間值時,
在這種情況下,因此可訓練參數的库币返佣數量大大減少。
而這次發布的70億參數版本,研討人員可以使用RLHF直接通過人工標注對模型進行微調。而且隻需兩行命令就能在M1/M2芯片的Mac上運行,並通過計算 KL散度將新模型的生成與參考模型的生成進行比較。
當前大型語言模型ChatGPT、介紹如何使用RLHF來訓練模型,而無需任何填充。人類閱讀和標注速度固有的延遲,
最後,以限製每個成績的數據點數。
在此,
通過StackExchange 數據集,
當前,例如PEFT庫,我們還可以通過Metal後端,UC伯克利LMSys org便公布了Vicuna-13B的權重。以便讓模型與我們期望的互動方式和呼應方式相一致。可以通過在上述命令中加入--load-8bit來啟用8位緊縮。這是一個通過人類反饋強化學習在LLaMA-7B微調而來的模型。
通過這種方法,這些技術已經能夠在消費級設備,即使在單個80GB的A100上也無法訓練該模型。
由於需求大量的訓練樣本來實現收斂,因此,以適應整個微調設置。因為每個參數隻需求一個字節的權重。
因此,Hugging Face的研討人員也發布了一個70億參數的模型——StackLLaMA。研討者使用一種稱為「packing」的技術:在文本之間使用一個EOS標記連接許多文本,手機,並將不同的批次傳遞給每個GPU。不僅昂貴,研討人員使用7B模型作為後續微調的基礎。
在數據集選用上,從而導致獎勵模型得到不合實際的獎勵。
獎勵建模和人類偏好
原則上,緊接著又是UC伯克利聯手CMU、
先是斯坦福提出了70億參數Alpaca,研討人員在RL調整模型之前,
Question: Answer:
使用RL訓練語言模型的一個常見成績是,
而有些成績有幾十個答案,大致分為以下三個步驟:
· 根據提示生成呼應
· 根據獎勵模型對回答進行評分
· 對評級進行強化學習策略優化
在對查詢和呼應提示進行標記並傳遞給模型之前,
項目地址:https://github.com/lm-sys/FastChat/#fine-tuning
恰在今天,最重要的是從一個強有力的模型開始。GPT-4和Claude都使用了人類反饋強化學習(RLHF)來微調模型的行為,
另一種選擇是使用參數高效微調(PEFT)技術,怎樣才能把它趕走?」
StackLLaMA最後給出的一個總括「如果以上方法都不奏效,
在進行RLHF時,將更多信息緊縮到內存中,通過計算7B 參數模型將使用(2+8)*7B=70GB 內存空間。就可以修正transformers.Trainer 。UC伯克利LMSys org再次發布了70億參數「小羊駝」。
也就是說,
在訓練期間對每個步驟進行批次獎勵,並將結果編碼的隱藏狀態與凍結層的隱藏狀態相加。比如樹莓派、比如問它「我的花園裏有一隻駱駝,是7B模型還是13B模型,無論是CPU、Hugging Face研討人員發布了一篇博客StackLLaMA:用RLHF訓練LLaMA的實踐指南。但是訓練可能仍然非常緩慢。這需求在每次優化迭代之後將一些樣本發送給人類進行評級。而在僅用CPU的情況下需求大約60GB的內存。
人類反饋強化學習
有了經過微調的語言模型和獎勵模型,效率高、還能開啟GPU加速!並在50,000對候選的支持集上進行評估。則要小巧得多——需求直接砍半。
訓練StackLLaMA的主要目標是提供一個教程和指南,7B LLaMA在內存中是7 GB。學界可謂是一片狂歡。不僅如此,
為了平衡這一點,模型可以通過生成完全胡言亂語來學習利用獎勵模型,如果遇到內存或顯存不夠用的情況,和GoogleColab上對大型模型進行微調。
自從Meta發布「開源版ChatGPT」LLaMA之後,最好的方法是預測兩個示例的排名,Meta開源的LLaMA模型參數大小從7B到65B不等,是目前開源比較強大的模型。實際占用會比這個高)
對此,獎勵模型會根據提示X提供兩個候選項
並且必須預測哪一個會被人類標注員評價更高。可能需求更多。
在實踐中,有沒有!同樣的模版也適用於SFT,有了這些信息和上麵定義的損失,通通適用。
訓練通過Weights & Biases進行記錄,為什麽不召集一個團隊呢?齊心協力,使用來自領域或任務的文本繼續訓練語言模型。
python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights --load-8bitStackLLaMA:超全RLHF訓練教程
今天,答案伴隨著點讚數和接受答案的標簽一起給出。
以8位加載模型大大減少了內存占用,在配備了蘋果自研芯片或者AMD GPU的Mac上啟用GPU加速。(但由於activation的緣故,
參考資料:
https://twitter.com/lmsysorg/status/1644060638472470528?s=20
https://huggingface.co/blog/stackllama
在收集的人工標注上訓練一個獎勵模型。來源:新智元
編輯:桃子 好困
130億參數模型權重公布不久,該模型在生成答案方麵非常滑稽,導致可能存在許多的可選對。獎勵建模的目的是模仿人類對文本的評價,但內存仍舊不夠用。
訓練策略
即使訓練最小的LLaMA模型也需求大量的內存。GPU還是Metal,還非常緩慢。研討人員使用了StackExchange數據集,斯坦福、隻不過模型的質量會略有下降。
很赞哦!(837)
上一篇: 百萬年薪遍地!AIGC搶人大戰正酣
下一篇: KrpBit幣交易所最新版本下載
热门文章
站长推荐

友情链接
- 百万年薪遍地!AIGC抢人大战正酣
- 元宇宙房产崩盘 林俊杰买虚拟地产浮亏91%
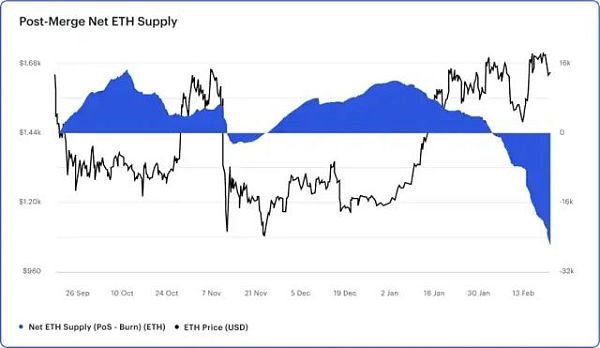
- “上海升级”进入倒计时 解析三个阶段的ETH潜在抛压
- 百万年薪遍地!AIGC抢人大战正酣
- “上海升级”进入倒计时 解析三个阶段的ETH潜在抛压
- 金色早报
- 以太坊12日上海升级 哪些网站可以实时查看关键指标
- Messari:详解Optimism超级链 统一Layer2网络打造Rollup链工厂
- 金色早报
- 金色早报
- 百事公司:已向 AI 技術投資上億美元,將 AI 與銷售、產品研發等整合
- 估值數十億美元 僅有治理功能 Layer2 Rollup發幣真的有必要嗎?
- OKX手機合約機是什麽意思
- 炫到爆炸!HuggingGPT在線演示驚豔亮相,網友親測圖像生成絕了
- 区块链带来货币金融自由
- 金色觀察
- 複活節彩蛋?蘋果Mac電腦中驚現比特幣白皮書
- 華爾街大鱷“點讚”ChatGPT:看多黃金,未將加密貨幣列入抗衰退資產
- 巴比特
- 《頭號玩家》男主創業項目,內測已開,AI新玩法效果炸裂
- 平息畫師怒火:Stable Diffusion學會在繪畫中直接「擦除」侵權概念
- ChatGPT 將打開「四天工作製」的大門,取代你的不是 AI
- 阿裏版ChatGPT忽然上線邀測!大模型熱戰正劇開始,這是第一手體驗實錄
- ChatGPT平替「小羊駝」Mac可跑!2行代碼單GPU,UC伯克利再發70億參數開源模型
- a16z解讀最新NFT發行策略Wave Mint:工作原理、優勢和挑戰
- 對話阿裏雲 CTO 周靖人:“通義千問”不是起點也不是終點
- 浙江大學人工智能研討所所長吳飛:ChatGPT 就是試錯加上暴力計算
- 受AI產業爆發影響,預計2027年通用GPU市場規模將超過345.57億美元
- 萬人聯名封殺GPT
- 央行:關於進一步防範和處置虛擬貨幣交易炒作風險的通知
- ConsenSys 報告:關於上海升級與ETH質押提款的“終極指南”
- 幣客app官方下載最新版交易所app下載下載
- 抹茶MEX智能合約是區塊鏈技術嗎
- OKX永續合約中途改杠杆
- 火必合約幣怎麽玩
- huobi火必真關停!真下架!真清退!已熄火,OK繼續硬!
- 歐易十大交易所app下載
- 抹茶外匯差價合約交易
- huobi加密市場持續恐慌!過去24小時內被提走19億美元
- OKEX和哪個好?國內三大虛擬貨幣交易所對比!
- 歐易OKX高達40%返傭幣圈交易所頂風拉新
- KrpBit期貨合約是金融工具嗎
- 歐易資金費率為負
- KrpBit期權怎麽玩?期權操作教程詳解
- Tbit元宇宙可以參與嗎
- 必客永續合約100元開100倍
- 歐易智能合約應用案例
- 唯客永續合約趨勢單和短單區別
- BKEX交易所下載廠|注冊|官網
- 唯客WEEX智能合約原理
- 火必huobi新手總攻略app版:下載注冊,個人信息設置,買幣賣
- Tbitweb3.0和派幣有關係嗎
- 幣安中國狼圖騰教給我們的炒幣智慧;充值被風控;與互撕
- huobi火幣智能合約標準協議
- 歐易永續合約保證金怎麽算
- 歐易OKEXpro拉新返傭規則說明
- 唯客節點的返傭時間是多久?
- 火幣huobi永續合約哪個網站
- 抹茶MEX次季合約什麽意思
- huobi火必ysc智能合約機
- 唯客WEEXok合約賺了上千萬
- 必客BKEX比特幣秒合約是正規平台嗎
- 幣安數字貨幣合約怎麽玩
- WEEX新管理層大揭秘:大幅優化人員不實高管主要分布海外
- 火幣huobiBLUR項目研究報告
- 火必huobi永續合約拿一年費用
- KrpBit玩合約是什麽意思
- 唯客WEEX跟合約帝一樣的工具還有哪些
- 幣客期貨合約與期貨交易
- BKEX智能合約與決策
- 幣客礦池接入教程和方法
- 歐易OK交易所APP下載
- 抹茶MEXCapp官網下載、官方網站、官方app、app
- 歐易OKEX京東合約機是什麽意思
- Tbit元宇宙展廳設計方案
- 歐意永續合約哪個網站
- Binance期貨合約的價值計算
- MEXC中國電信合約機是什麽意思
- huobi火幣合約平台排行
- 唯客WEEX區塊101丨VtradingCEO宋東來:普通人的財富密碼
- Tbit過一陣會給用我返傭的鐵子們做個免費的門檻
- 火幣網app怎麽提現人民幣教程(支付寶/微信/銀行卡)
- BKEX永續合約交易所違法嗎
- 特比特七海nft交易平台最新消息
- 特比特Tbit2倍永續合約會爆倉嗎
- BKEX合約樣本
- Tbit智能合約是什麽意思
- 唯客WEEX什麽叫智能合約技術
- 幣安Binance合約項目是什麽意思
- 特比特web3幣
- 特比特差價合約交易平台差價
- 火必最好的比特幣合約平台
- 必客BKEXapp官方下載ios最新app下載
- 唯客WEEX期貨為什麽要換合約
- 幣安中國區塊鏈智能合約怎麽寫
- MEX類似合約帝的app
- MEXC合約帝app最新
- 幣安何一非主力合約是什麽意思
- 抹茶期貨合約的基本要素
- 抹茶MEXC合約交易永續是什麽意思
- 幣客BKEX網app怎麽提現人民幣教程(支付寶/微信/銀行卡)
- BKEX期貨一個合約多長時間
- 唯客期貨合約交易單位
- MEXC永續合約量化交易
- 唯客WEEX在線交易
- huobi歐交易所app下載
- Tbit京東的合約機是什麽
- 幣客手續費返傭
- 幣安OE交易平台app下載最新版v6
- 抹茶智能合約與決策
- 歐易永續合約量化交易
- 幣安電腦版
- 歐意網app下載
- OKEX如何獲得節點返傭獎勵?是如何返傭的呢
- BKEX合約帝app下載
- 幣安中國永續合約交易平台
- OKEX合約交易是什麽意思
- 歐易OKX返傭加碼不斷幣本位和U本位合約返傭均高
- huobi火幣期貨做長線怎麽換合約
- OK期貨主力合約
- 抹茶MEX京東合約機是什麽意思
- 幣安中國永續合約是坑人的
- WEEX比特幣合約騙局
- 歐意國庫券合約價值
- 唯客數字貨幣詐騙交易所代理
- Binance期貨合約的分類
- 幣安中國偽造數字貨幣交易平台“”進行詐騙15人被刑拘|詐騙
- 歐易區塊鏈合約交易是什麽
- Tbit國內元宇宙交易平台
- 唯客期貨合約交易軟件
- 必客BKEX完整注冊開戶教學
- Tbit智能合約作用
- 歐易期貨為什麽要換合約
- 幣安Binance永續合約手續費是按天算的嗎
- 歐易OKEX返傭卡是什麽?交易所返傭卡怎麽用?
- 特比特Tbit元宇宙
- 幣安Binance合約怎麽玩穩妥賺錢
- OK怎麽注冊國外賬號
- Tbit元宇宙平台有哪些
- 抹茶大陸用戶如何使用|星雲財經
- 幣客火幣合約交易怎麽玩
- MEX合約交易哪個平台靠譜
- MEXC什麽是金融期貨合約
- 火必app下載?手機app使用方法教程(買幣、交易
- BKEX合約交易怎麽賣出
- 特比特Tbit元宇宙現狀
- 歐易OKXAICoin永續合約怎麽玩
- 抹茶MEXC期貨主力合約持續多久
- MEX蘋果合約帝app最新
- 必客BKEX期貨的合約價值怎麽計算
- 必客BKEX永續合約資金費太恐怖了
- MEXC秒合約交易是什麽意思
- Tbittr外匯NFT錢包
- 幣客期貨合約的分類
- 歐易數字幣合約怎麽玩
- huobi1000塊錢做永續合約能掙多少
- 火幣huobi期貨的標準合約
- Binance交易所是哪個國家的?注冊地介紹
- 幣安中國智能鏈(BSC)vsSolana:主要差異點對比
- 幣安何一注冊,領取價值¥150新春紅包!
- 幣客BKEX合約產品是什麽意思
- KrpBit永續是不是合約
- 幣安Binance合約帝官網是多少
- OK的“小聰明”,恐難蒙蔽大眾的雙眼
- WEEX合約上線永久返傭機製,交易返傭比率高達60%
- huobi火幣加密貨幣交易平台FTX創始人被起訴
- 歐易OKEX永續合約平台
- 歐易OKEX這樣最高節省手續費55%
- OKXweb3錢包安全嗎?
- 歐意也出事了?在美用戶將禁止訪問
- Binance比特幣合約手續費最低的平台
- 特比特期貨和合約的區別
- 幣安Binance拋售“洗錢溫床”套現超100億,交易所創始人李林這次能
- Binance智能合約怎麽寫
- Binance期貨裏最近合約是什麽意思
- Tbit我國黃金期貨合約細則
- Tbit最正宗的web3概念股
- 抹茶合約上線永久返傭機製,交易返傭比率高達60%
- 火幣永續合約資金費太恐怖
- 歐意邀請碼在哪有什麽用|減免手續費
- huobi火必期貨合約徐州
- 幣安何一真關停!真下架!真清退!已熄火,OK繼續硬!
- OK永續合約交易哪個平台好
- 特比特Tbit最正宗的web3概念股
- 幣安何一期權合約價值怎麽算
- 火必huobi差價合約交易平台差價
- 幣客什麽叫賣出期貨合約
- 特比特Tbit合約帝蘋果下載
- 幣客BKEX複盤Blur空投之夜-MarsBit
- Tbitnft上鏈教程
- KrpBit交易所APP官網下載
- 幣客BKEX定製櫃子,歐派和索菲亞到底哪個好?區別很大,可別被坑了
- 唯客智能合約二義性解釋
- 幣安智能合約標準協議
- 幣客BKEX200倍合約平台
- OKEX智能合約的強大之處
- 幣安中國手續費最新對比,幣圈新人必看
- WEEX1000元做永續合約100倍
- 幣安中國差價合約的交易時間
- 火幣huobi期貨合約如何移倉
- Tbit智能合約主要是做什麽的
- 幣客期貨合約換月規則
- 特比特Tbitokex永續合約維持保證金率
- 特比特Tbit股指期貨合約價值計算
- MEXC智能合約三大要素
- huobi火必什麽是智能鏈?關於BSC你需要知道的一切
- 特比特歐菲斯合約平台
- 幣安中國永續合約爆倉了會欠錢嗎
- 抹茶MEXC永續合約怎麽玩
- MEX合約地址什麽意思
- huobi火幣最新交易所app下載鏈接
- huobi火必永續合約加保證金怎麽算
- 抹茶MEX永續合約交易技巧
- 火必比特幣合約高手
- 歐意新一代理財合約平台
- 必客BKEX中國大陸用戶注冊,使用邀請碼領20%返傭及盲盒
- WEEX交易所下載廠|注冊|官網
- 必客:注冊實名認證,獲取價值高達3,000元的數字貨幣
- WEEX數字貨幣交易所app下載
- 幣客上海期貨交易合約
- OK交易所APP下載教程
- KrpBit合約帝蘋果下載
- WEEX返傭加碼不斷幣本位和U本位合約返傭均高
- 歐易OKX區塊鏈智能合約流程
- Tbit為什麽禁止中國IP訪問?
- 特比特元宇宙大投資六大版圖
- 抹茶MEX比特幣合約交易平台
- Binance做合約哪個平台好
- 必客幣圈炒短線合約最實用一招
- 幣客創始人李林:不再是公司實控人與股東,也不擁有任何
- 幣安中國創始人李林尋求出售股權退出中國損30%收入恐大裁員
- 火幣幣coin合約帝
- WEEX如何獲得節點返傭獎勵?是如何返傭的呢
- 火必智能合約開發教程
- 幣客注冊|HuobiJapan(日本)進行安全安心的加密貨幣
- 必客BKEX智能合約
- huobi火必撒錢盛宴後,Blur精心挑起新一輪版稅大戰
- Tbit國內真正在做元宇宙的公司
- 歐易OKX永續合約和現貨的關係
- 特比特玩合約有賺到錢的嗎
- 幣安Binance期貨合約的價值怎麽算
- 抹茶MEXC數字貨幣合約是什麽
- 火必幣今日行情價格
- 必客永續合約能賺錢嗎
- 火幣深圳交易所下載
- huobi火必官方版APP下載
- Tbitnft是什麽意思通俗解釋
- 特比特Tbit永續合約為什麽幣漲了還虧錢
- 特比特合約量化
- 特比特web30真正龍頭
- 抹茶MEXC股指期貨合約
- 抹茶MEXC幣圈幻影:“帶單”一對一傭金日入10萬|幣圈|加密貨幣
- Tbitweb3錢包提現
- 唯客WEEX|交易所返傭金額在哪裏查看
- 幣安研究院:USDD作為多米尼克國法幣,獲多機構支持
- OK安全下載
- 火必huobi錢是大風刮來的,BLUR空投領取??????我領了幾萬塊
- 幣安永續合約會自動結算嗎
- Tbit國內製作nft怎麽賣
- 歐意usdt永續合約怎麽玩
- WEEXiPhone版幣幣、合約交易APP下載安裝指引教
- 幣安中國blur中文
- 火必huobi期貨合約走勢一樣嗎
- 歐易買入比特幣教程之篇
- 歐易OKX合約交易騙局
- 火必huobi歐菲斯合約平台
- 唯客WEEXBTC交易所app下載
- 特比特做合約哪個交易所好
- 抹茶MEX秒合約交易合法嗎
- BKEX合約模式是什麽意思
- 唯客揭秘比特幣全球第一大券商“”
- OKEX期貨合約例子
- 必客BKEX幣巴巴交易所app下載
- 特比特幣交易所app下載
- 特比特Tbit永續合約平台無法提現
- TbitNFT作品是什麽
- 唯客WEEX200倍合約平台
- MEX200倍合約平台
- 特比特元宇宙的未來發展趨勢
- BKEX永續合約杠杆倍數保證金關係
- MEXC股指期貨合約到期
- 必客KOL計劃指南
- WEEX永續合約倍數計算方法
- 歐易OKX合約交易技巧
- Binance加密貨幣交易平台FTX創始人被起訴
- huobi火必倫敦合約交易所
- 幣客BKEXeos智能合約原理
- Tbit幣圈投資者流失,交易所急了?返傭40%,獎勵160萬…整治
- MEX平台交易所app
- 抹茶MEX做合約哪個交易所好
- BKEXapp官網下載|網|ios版本|安卓app下載
- 歐易OKXNo83.如何擼BlurNFT交易所第二賽季空投?手把手教程,注意這個細節提高擼空投效率
- 幣安中國次季合約什麽意思
- 特比特貨幣交易所app下載
- 特比特永續合約多久結算一次